BGP
BGP 基础
BGP 特征
- BGP是外部路由协议,用来在AS之间传递路由信息。
- 是一种路径矢量(Path-Vector)矢量路由协议(AS_PATH)。
- 可靠的路由更新机制(TCP)(目的端口为179,源端口随机生成)
- 丰富的Metric度量方法(12条选路原则)。
- 从设计上避免了环路的发生
- 为路由附带属性信息。
- 支持CIDR(无类别域间选路)。
- 丰富的路由过滤和路由策略(router-policy)。
- 无需周期性的更新,只存在触发更新,并且值更新部分路由。
- 周期性(60s)的发送KeepAlive报文检测TCP的连通性。
BGP 报文种类
- Open: 负责和邻居建立邻接关系
- Keepalive: 该消息在对等体之间周期性质的路由信息更新,用于维护TCP的连接(60s)
- Update: 该消息被用来在BGP对等体之间传递路由信息。(通告和撤销路由)
- Notification: 当BGP Speacker检测到错误的时候,就发送给消息给对等体
- Route-Refresh: 用来通知对等体自己支持路由刷新能力。
BGP 邻居
BGP的邻居关系: BGP邻居关系建立在TCP连接的基础之上。 可以通过IGP或静态路由来提供TCP连接的可达性。
注:BGP的邻居是通过单播的方式建立的,所以首先需要在BGP进程下手动配置邻接地址。BGP没有自动发现邻居的机制,只能手动建立。
BGP中影响邻居建立的条件: 1. 停留在Idle状态。 没有到达Peer的路由条目。 EBGP多跳。(不去发送TCP的建立连接报文) 2. 停留在Connect或者Active状态 源地址错误。(查看对端的IP地址是否是本地指定的邻居地址) TCP的认证。(TCP MD5) 有到达peer的路由,但是路由错误。 过滤了TCP的报文。
BGP 状态机
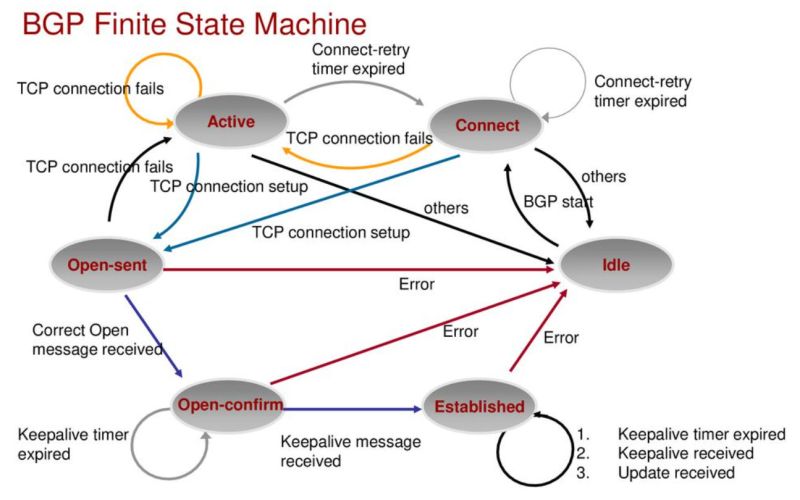
Idle:BGP连接的第一个状态。在空闲状态,BGP在等待一个启动事件。启动事件出现以后,BGP初始化资源,复位连接重试计时器(Connect-Reitry),发起第一条TCP连接,同时转入Connect(连接)状态。
Connet:在此状态,BGP发起第一个TCP连接,如果连接失败,则进入到active状态。如果TCP连接成功,就转入OpenSent状态,如果TCP连接失败,就转入Active状态。
Active:在此状态,BGP总是在试图建立TCP连接,如果连接重试计时器(Connect-Retry)超时,就退回到Connect状态,如果TCP连接成功,就转入OpenSent状态,如果TCP连接失败,就继续保持在Active状态,并继续发起TCP连接。
OpenSent:在此状态,TCP连接已经建立,BGP也已经发送了第一个Open报文,剩下的工作,BGP就在等待其对等体发送Open报文,并对收到的Open报文进行正确性检测,如果有错误,系统就会发送一个条出错的通知消息并回退到Idle状态。如果没有错误,BGP就开始放KeepAlive报文,并复位KeepAlive计时器,开始计时。同时转入OpenConfirm状态。
OpenConfirm:在此状态,BGP等待一个KeepAlive报文,同时复位保持计时器,如果收到一个KeepAlive报文,就转入Established阶段,BGP邻居的关系就建立起来了。
Established:在此状态,BGP邻居关系已经建立,这时,BGP将和它的邻居们交换Update报文,同时复位保持计时器。
另外,在除Idle状态以外的其他五个状态出现任何ERROR的时候,BGP状态机就会回退到Idle状态。在BGP对等体建立的过程中,通常可见的三个状态是:Idle,Active,Established。
Idle状态下,BGP拒绝任何进入的连接请求,是BGP的初始状态。
BGP路由通告原则
-
连接建立时,BGP Speaker只把本身用的最优路由通告给对等体。
-
多条路径时,BGP Speaker只选择最优的路由放入路由表。
-
BGP Speaker从EBGP获得路由会向它所有的BGP对等体通告(包括EBGP和IBGP)。
-
通告给EBGP时,下一跳为自己。(注:如果通告路由的EBGP邻居需要接收的的EBGP邻居在同一网段,则通告时不修改下一跳。)
-
通告给IBGP时,不更改下一跳。防止次优路径。
-
-
BGP Speraker从IBGP获得的路由不会通告给其他的IBGP邻居。
-
IBGP的水平分割原理:从一个IBGP邻居收到的路由条目不会再通告给其他IBGP邻居。
-
如果想让所有的IBGP邻居都能收到路由,有三种解决方案:
- 全互联(每两台设备之间都建立IBGP邻居)。
- RP(路由反射器)。
- 联盟
-
-
BGP与IGP的同步。从IBGP邻居学来的路由信息:
如果同步关闭:会将从IBGP学到的路由传给eBGP邻居
如果同步开启:BGP不将从IBGP对等体获得的路由通告给它的EBGP对等体,除非该路由信息也能通过IGP获得。
先查找自己的IGP。如果IGP里面有这个网络,就把这个网络传给eBGP;如果IGP里面没有这个网络,就不会传给eBGP邻居。
BGP同步规则的目的: 防止一个AS(不是所有的路由器都运行bgp)内部出现路由黑洞,即向外部通告了一个本AS不可达的虚假的路由.
BGP 选路策略
BGP 之所以被称为“最强大的路由协议”,不是因为它跑得快,而是因为它最听话。OSPF 选路只看带宽(Cost),而 BGP 有一套极其复杂的“十三步过滤法”,允许管理员通过各种手段人为干预流量。
BGP 选路核心原则(按优先级排序)
第一关:Weight (权重 - 思科私有) 规则: 仅在当前路由器有效,值越高越优。
用途: 如果一台路由器有两个出口,你想让它强行走其中一个,就改这个。
第二关:Local Preference (本地优先级) 规则: 在整个 AS 内部有效,值越高越优。
地位: 这是 IBGP 选路最常用的工具。
场景: 告诉公司内部所有人:“出网流量请优先走 A 运营商,因为他们家便宜!”
第三关:AS-Path (AS 路径长度) 规则: 经过的 AS 数量越少越优。
地位: 这是 EBGP 选路最直观的标准。
技巧: “AS-Path 预挂”(Prepend)。如果你不想让别人从某条路进你公司,你可以故意在路径里多写几次自己的 AS 号,让这条路看起来很长。
第四关:Origin (起源) 规则: IGP(通过 network 命令产生的)> EGP > Incomplete(重发布进来的)。
逻辑: 户口越正宗的路由越靠谱。
第五关:MED (Multi-Exit Discriminator) 规则: 值越小越优。
地位: 它是“外交官”发给邻居的建议。
场景: 告诉隔壁 AS:“当你发数据给我时,请优先走我这边的 1 号口,别走 2 号口。”
第六关:EBGP 优于 IBGP 规则: 从外部学到的路由,比从自家兄弟(内部)学到的优先级高。
逻辑: 既然外面已经有路了,就别在家里转圈了,赶紧发出去。
第七关:Router ID (最后的平局打破者) 规则: 比到最后还没分出胜负?那就看谁的 Router ID 小。 逻辑: 总得选一个,就像抛硬币一样。
选路的优先级: Weight > Local Preference > AS-Path > Origin > MED > EBGP > Router ID
Origin (起源属性) 在 BGP 的世界里,身份背景非常重要。当路由器收到去往同一个目的地的多条路由时,它会看这条路由最初是怎么被“发明”出来的。
MED (Multi-Exit Discriminator) MED(多出口区分符)是 BGP 选路中非常特殊的一个,因为它是一个“外交建议”。 场景模拟: 假设你的公司 (AS 100) 在北京和上海各有一根线连着中国电信 (AS 200)。 你希望电信发给你的流量优先从北京进。 这时,你可以在北京的路由器上给电信发路由时,带上 MED = 10。 在上海的路由器上发路由时,带上 MED = 100。 规则: MED 值越小越优。电信的路由器看到后,会发现北京入口的“代价”更小,于是把流量丢给北京。
MED 的关键细节: 控制“进站”流量: 它是你发给邻居的,用来告诉邻居怎么进你家门。(对比:Local Preference 是告诉自家兄弟怎么出门)。 不传下一家: 这是一个非常“害羞”的属性。AS 100 发给 AS 200 后,AS 200 的路由器自己用,但它绝对不会再把这个 MED 传给 AS 300。 默认只比邻居: 路由器默认只比较来自同一个 AS 的路由的 MED。如果两个路由来自不同的 AS(一个电信、一个联通),BGP 默认不比 MED(直接跳过这一关),除非你开启了特殊的强制比较命令。
EBGP 和 IBGP
EBGP (External BGP): 运行在不同 AS 之间(比如你的公司连接电信、连接腾讯云)。 IBGP (Internal BGP): 运行在相同 AS 内部(比如你公司机房内部的路由器之间)。
为什么内部(数据中心)也要跑 BGP? 你问得很好:“难道内部也应用 BGP 管理?” 答案是:是的,尤其是现代大规模数据中心。
在传统网络中,公司内部跑的是 OSPF 或 EIGRP(这些叫 IGP)。但随着数据中心变大(比如 Clos 架构),BGP 进场了。
场景 A:作为“出口”的 BGP (传统用法) 在这种场景下,你公司的 BGP 路由器就是“外交官”:
你公司有一个或两个高性能路由器作为 EBGP 节点。
它们负责向互联网运营商(ISP)宣告:“1.1.1.0/24 这个网段在我这里!”。
内部呢? 内部路由器通过 OSPF 把流量丢给这两台出口路由器。
IBGP 的作用: 如果你有两个出口路由器(A 和 B),它们之间需要跑 IBGP。这样 A 才知道 B 从外面学到了哪些路,互通有无。
场景 B:作为“骨架”的 BGP (现代 Clos/数据中心用法) 在现在的阿里、腾讯或 AWS 内部,OSPF 几乎不见了,全是 BGP:
Leaf 和 Spine 之间全跑 BGP。
原因: OSPF 在成千上万台交换机面前,计算开销太大,容易崩。而 BGP 非常稳定,且支持多路径负载均衡 (ECMP) 非常出色。
在这种情况下,每一层交换机都可能是 IBGP 关系,也可能是 EBGP 关系(取决于 AS 号怎么分配)。
水平分割
- 什么是 BGP 的水平分割?BGP 的水平分割在 EBGP 和 IBGP 中表现得完全不同:
A. EBGP 的水平分割(靠 AS-Path)这是最直观的。EBGP 路由器在发送路由时,会带上自己的 AS 编号。规则: 如果一个路由器收到一条路由,发现路径(AS-Path)里已经包含了自己的 AS 号,它就会丢弃这条路由。目的: 防环。如果我发出去的东西绕了一圈又回到我这里,说明出环了。
B. IBGP 的水平分割(核心难点)在同一个 AS 内部,AS 号都是一样的,没法靠 AS-Path 防环。于是 BGP 规定了一个死理:规则: 从一个 IBGP 邻居学到的路由,不能再转发给另一个 IBGP 邻居。直白解释: A 传给 B,B 收到后自己用,但 B 绝对不能传给 C。
- 为什么要有 IBGP 水平分割?(防环的代价)假设没有这个规则:
路由器 A 把路由传给 B B 传给 C C 又传回给 A。
由于大家都在同一个 AS 100 里,BGP 无法通过 AS 号判断这是否是重复信息。为了绝对禁止 AS 内部产生环路,BGP 设计者索性规定:内部只许传一次。带来的麻烦:这导致了一个问题:如果公司里有 A、B、C 三台路由器,A 学到了外界路由,传给了 B,但 B 不传给 C。那么 C 永远不知道这条路由。传统解决办法: 全互联 (Full-Mesh)。让 A 和 C 也建立 IBGP 邻居。后果: 如果你有 100 台路由器,你需要建立 \(100 \times 99 / 2 = 4950\) 个邻居关系。这简直是运维的噩梦。
- 救星:路由反射器 (Route Reflector, RR) 为了打破 IBGP 水平分割的禁锢,同时不用搞劳民伤财的“全互联”,RR(路由反射器) 登场了。
RR 的原理: 我们将某一台路由器(通常是性能最强的核心交换机)定义为 RR,其他路由器定义为它的 Client(客户机)。
打破规则: RR 收到 Client 发来的路由后,允许把它“反射”给其他的 Client。
形象理解: RR 就像是一个“班长”。原本同学之间(IBGP)不准私下传话(水平分割),现在规定:所有话都先传给班长,由班长统一站在讲台上大声重复一遍。这样所有人都能听到了。
关键细节: Originator_ID 和 Cluster_List: 为了防止 RR 反射时出环,BGP 给路由加了新的“标记”。如果 RR 看到路由标记里有自己的 ID,就知道出环了,会立刻丢弃。
Route Reflector
在 BGP 的世界里,Route Reflector (RR,路由反射器) 就像是一个“打破僵局的规则破坏者”。
为了理解它,我们必须先回到 BGP 内部的一个死理——IBGP 水平分割原则。
- 为什么要发明 RR?(问题的起因) 正如我们之前聊过的,BGP 规定:从一个 IBGP 邻居学到的路由,不能再传给另一个 IBGP 邻居。
如果不打破这个规则: 公司里有 3 台路由器 A、B、C。A 从外界学到了路由传给 B,B 却不能传给 C。为了让 C 知道,A 必须直接连一条线(建立邻居)给 C。
后果: 当路由器变多时,你需要建立 Full-Mesh(全互联)。如果你有 100 台路由器,你需要配置 4950 条邻居关系!这在管理和设备性能上都是灾难。
RR 的出现,就是为了让你不需要“全互联”也能传路由。
- RR 的角色与“反射”规则 在一个配置了 RR 的网络中,路由器被分为两种角色:
RR (Route Reflector): 班长/核心。
Client (客户机): 普通组员。
当 RR 收到路由时,它会违反水平分割原则,像镜子一样把路由“反射”出去:
从 Client 学到的路由: 反射给所有其他 Client 和非 Client。
从非 Client(普通的 IBGP 邻居)学到的路由: 反射给所有 Client。
结论: 只要把核心设备设为 RR,所有的 Leaf 或边缘设备设为 Client,信息就能像波浪一样传遍整个公司。
- RR 如何防止环路?(两个新属性) 既然 RR 打破了“不准传第二次”的禁令,那就面临出环的风险。为了解决这个问题,RR 给路由贴了两个“防伪标签”:
Originator_ID(始发者 ID):
记录这条路由是谁最先发出来的。如果路由绕了一圈回到始发者手里,它一看 ID 是自己,直接丢弃。
Cluster_List(簇列表):
记录路由经过了哪些 RR。如果 RR 收到一条路由,发现自己的“班级编号”已经在列表里了,说明在 RR 之间打环了,直接丢弃。
- RR 在 Clos 架构中的应用 在数据中心(如两层 Leaf-Spine)中:
Spine 交换机 通常被配置为 RR。
Leaf 交换机 被配置为 Client。
这样,Leaf 1 产生的一条服务器路由传给 Spine,Spine 就会把它反射给 Leaf 2、Leaf 3…… 整个数据中心就通了。
- 总结:RR 的优缺点 优点: 极大简化了配置。你不再需要数千条邻居线,只需要每个 Client 连向 RR 即可。
缺点: 存在单点故障风险(如果 RR 挂了,全网路由不通)。所以通常会部署两个 RR(双备份)来保证安全。